Apache Cassandra is a key/value type NoSQL (A NoSQL database is a database system which provides storage and retrieval of data that uses looser consistency models .When comparing with traditional relational databases , NoSQL is more suitable for storing large volume of data .Cassandra database was developed by facebook. Now the development of Cassandra is under Apache Foundation.As of now , Cassandra is used by many enterprises around the globe. More and more customers are accepting Cassandra for their enterprise application back end.This chapter gives a basic Apache Cassandra Tutorial
Apache Cassandra vs Traditional Databases
A brief comparison is shown below.
1)Big data is the data which exceeds the capacity of traditional relational databases. Cassandra is the suitable database system for Big data applications.
2)Read/Write performance is higher for Cassandra
3)Chances of failure is very very minimal in Cassandra when comparing with relational databases.This is attained by replication of same data in multiple data centers in a cluster.
4)In case of Cassandra ,every node in a cluster has the same role. There is no master/slave mechanism in a cluster.So every node can service each request.
5)Cassandra has Key/value type architecture.It is entirely different from architecture of relational databases.
Apache Cassandra Architecture
Apache Cassandra violates the legacy master/slave architecture. In case of Cassandra each node in a cluster has the same responsibility. A cluster can have number of nodes in it. Each piece of data in a node is replicated in some other node. So chance for a failure is very minimal.
Cassandra Data Model
Column
A column is the smallest increment of data in Apache Cassandra. It has a column name , value and a time stamp.

Column Family
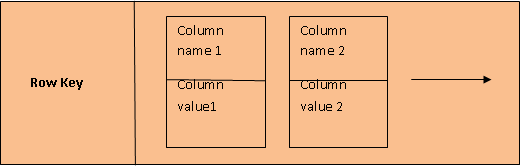
A Column family is a unit in which data is stored in Cassandra database. Each column family has a unique id known as row key.There will be multiple columns against a row key in a column family.Each column has its own column name and value.
Super Column
A super column has a key and a number of sub columns as values.There can be any number of sub columns in a super column.The columns will be in the sorted order of column names.
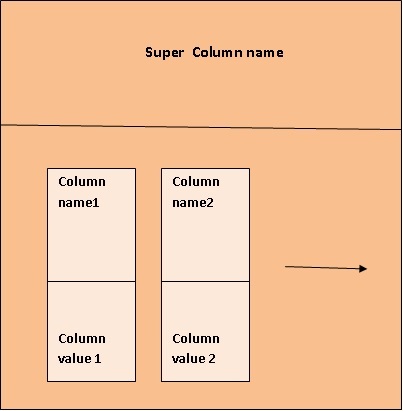
Super Column family
A super column family is almost similar to a column family.The difference is instead of columns here it is super columns.There can be any number of super columns in a super column family.Each super column can accommodate any number of columns.The super columns are arranged in sorted order of super column names.

keyspace
It is the container for our data.It is similar to schema in Relational Databases.
Write Process in Cassandra
1)When data is writing to Cassandra , first the data is going to a commit log.
2)Sending data to responsible nodes . Corresponding node is writing the data to memtable.
3)If the responsible node is down at the time when write attempt is happening, then data will be simply written to another node .It holds the data.Once the intended node comes up , then it is updating from the node which holds the data temporarily.
4)From the memtable data will be written to sstable.
Read Process in Cassandra
Reading of data is taking place in parallel across all nodes in a cluster. If the node with requested data is down then the data will be read from the node which is holding replica of the data required.
Cassandra Query Language(CQL)
The CQL is now widely used in cassandra client applications. It is simply providing an SQL like alternative to query the Cassandra database. The important keywords in CQL are :
SELECT,UPDATE ,INSERT ,TRUNCATE ,DROP etc.
Also there are few special statements in CQL. They are :
1)CREATE KEYSPACE
2)CRETE COLUMNFAMILY
3)CREATE INDEX
We will be using these things in our coming discussions
Data Types in Apache Cassandra
Internally Cassandra stores column names and values as hex byte array.When we create schema , we can provide the data type too.But it is not required.Cassandra treats everything as hex byte array.The data type of row key is called as validator and of column name is comparator.
In the coming sections we will be discussing various operations on Apache Cassandra with suitable examples.
See Related Topics
Configuring Apache Cassandra in local machine
Inserting data into Apache Cassandra using Java
Reading data from Apache Cassandra database using Java
Listing columns in a column family using Java
Inserting objects into Apache Cassandra using Hector API
Excellent tutorial. Can you talk about how to set up a cluster?
Found some useful info at
http://www.datastax.com/2012/01/how-to-set-up-and-monitor-a-multi-node-cassandra-cluster-on-linux
It uses python and linux boxes… prefer to see Java based setup/monitoring
Excellent tutorial.
Could you please elaborate the reading and writing process and include the information about shards,racks, routing etc.
There are also a lof of interesting tutorials and training videos on Parleys.com
Hello Carlo.It looks very good.Thank you for sharing the link.